
El artículo anterior explicaba cómo instalar y arrancar Potato OS en la Raspberry Pi 5. El sistema queda en marcha con el modelo Qwen3.5-2B-Q4_K_M descargado automáticamente. Funciona. Sin embargo, la pregunta llega sola: ¿es ese el mejor modelo que puede correr esta placa, o hay algo más capaz dentro del mismo límite de memoria?
La respuesta corta es que sí hay alternativas mejores. Encontrarlas, en cambio, lleva más trabajo del esperado. Este artículo cuenta exactamente ese proceso: los modelos que no pasan el corte, los que sí cargan, y cuál sale ganador en las pruebas de razonamiento. Probando patatas!!!
Hugging Face: cuenta, token y descarga con wget
Casi todos los modelos GGUF disponibles hoy se distribuyen a través de Hugging Face, el repositorio de referencia para modelos de lenguaje. Hasta hace poco era posible descargar modelos públicos sin cuenta. Eso ya no es así. Cualquier descarga directa devuelve ahora un error 401, incluso en repositorios de comunidad sin restricciones de licencia.
Crear una cuenta es gratuito y no requiere tarjeta. Basta con ir a huggingface.co/join, introducir correo electrónico y contraseña, y verificar la dirección. Una vez dentro, el siguiente paso es generar un token de acceso. En huggingface.co/settings/tokens aparece la opción de crear un token nuevo. Para descargar modelos es suficiente con el tipo Read. El sistema genera una cadena que empieza por hf_ y que hay que guardar.

Con el token en mano, la descarga desde la Raspberry Pi o desde cualquier equipo de la red se hace con wget añadiendo una cabecera de autorización:
wget --header="Authorization: Bearer hf_XXXXXXXXXX" \
"https://huggingface.co/bartowski/Qwen_Qwen3-4B-GGUF/resolve/main/Qwen_Qwen3-4B-Q4_K_M.gguf"Una vez descargado el fichero en el equipo local, se puede copiar a la Pi directamente con scp. El portal web de Potato OS también permite subir archivos desde el panel de Settings, aunque para ficheros de más de 2 GB la transferencia directa por SSH o la descarga conectado a la Raspberry Pi por SSH es más rápida.

El indicador de RAM del portal no es fiable
Al cargar cualquier modelo, el panel de Potato OS muestra un porcentaje de uso de memoria que alarma: 91% con el Qwen3.5-2B, 94% con el Qwen3-4B, 96% con el Gemma 3 4B. Esos datos llevan a pensar que no hay margen para nada más. Sin embargo, la realidad es otra.
El comando free -h ejecutado por SSH mientras cualquiera de esos modelos está activo muestra más de 6 GB disponibles. La diferencia no es un error: es cómo Linux gestiona la memoria.
free -h
total used free shared buff/cache available
Mem: 7.9Gi 1.7Gi 491Mi 16Mi 5.9Gi 6.1GiLos modelos GGUF se cargan en memoria mediante mmap, una técnica que mapea el fichero del modelo en el espacio de memoria del proceso sin copiarlo físicamente. Linux contabiliza ese espacio dentro de buff/cache, no como memoria ocupada. Esa memoria se puede liberar si el sistema la necesita. Por eso la columna available de free -h muestra los 6 GB reales, mientras el portal cuenta el buff/cache como consumo fijo.
El indicador del portal es, en ese sentido, engañoso. Para saber si un modelo va a caber, la referencia correcta es la columna available de free -h, no el porcentaje de la interfaz web.

Modelos que no pasan el corte
Con 6 GB disponibles y el sistema operativo funcionando, el límite práctico para el fichero GGUF está alrededor de los 4,5 GB. Varios modelos explorados no llegan a esa cifra o presentan otros problemas.
El Gemma 4 E4B de Google tiene trampa en el nombre. Pese a llamarse 4B, su fichero Q4_K_M pesa 4,9 GB y el UD-Q4_K_XL supera los 5 GB. Al intentar cargarlo, el proceso de inferencia agota la memoria y Potato OS se desconecta. El modelo descarga correctamente pero nunca llega a responder.
El Trinity-Nano-Preview Q6_K de Arcee AI ocupa 4,7 GB. Descarga sin problemas pero tampoco carga. El motivo es que durante el cambio de modelo Potato OS mantiene brevemente ambos ficheros en memoria, lo que supera el límite. Además, la cuantización Q6_K exige más recursos de inferencia que un Q4_K_M del mismo tamaño.
El Phi-4-mini de Microsoft descarga y tiene un tamaño razonable, pero su arquitectura no está soportada en la versión de ik_llama que incorpora Potato OS 0.7.2. El modelo queda en estado de carga indefinida.
Por último, los modelos de la familia GLM de Zhipu merecen mención aparte. Herramientas de estimación como llmfit los clasifican erróneamente como modelos pequeños porque confunden los parámetros activos del diseño MoE con el tamaño real del fichero. El GLM-4.5-Air tiene 110 mil millones de parámetros en total. Su versión Q4_K_M pesa casi 73 GB. No hay nada que hacer con él en una Pi 5.
Los que sí funcionan: resultados de razonamiento
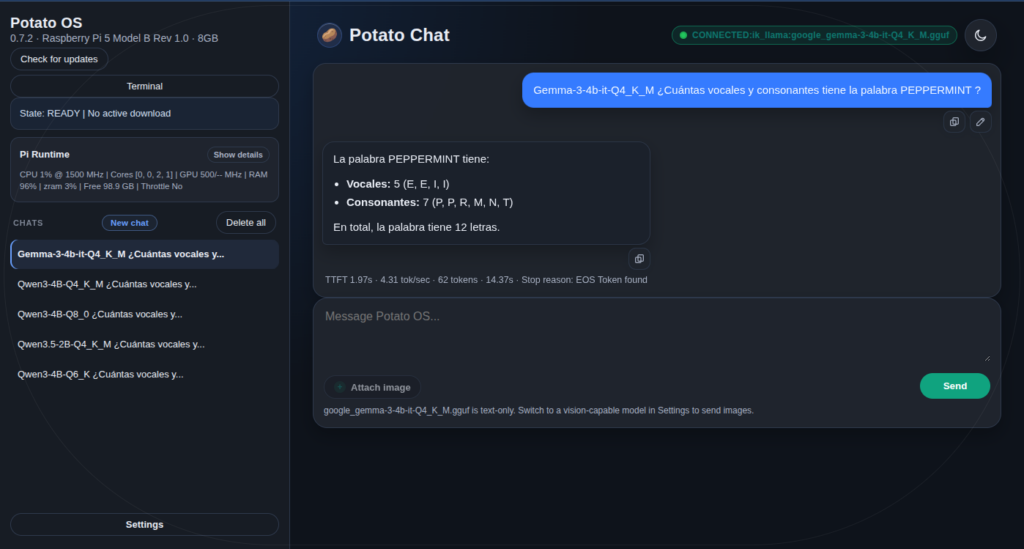
Tres modelos cargan y responden sin problemas. Para comparar el razonamiento de forma sencilla, la prueba consiste en pedir el recuento de vocales y consonantes de la palabra PEPPERMINT. Es un caso donde el modelo tiene que analizar letra por letra sin inventarse nada.
El Gemma 3 4B Q4_K_M responde en 14 segundos a 4,71 tok/seg, pero la respuesta es incorrecta: cuenta cinco vocales cuando son tres. También dice que la palabra tiene doce letras cuando tiene diez. El resultado llega rápido, pero no se puede fiar de él.
El Qwen3.5-2B Q4_K_M, el modelo por defecto de Potato OS, es el más rápido de los tres con 7,33 tok/seg. Sin embargo, también falla: inventa letras que no existen, se contradice en el recuento y llega a conclusiones distintas en diferentes partes de la misma respuesta.
El Qwen3-4B Q4_K_M responde a 4,14 tok/seg. El análisis es estructurado, va letra por letra y llega a la conclusión correcta en vocales. En consonantes se queda en seis en lugar de siete, un error menor de conteo final. Es, con diferencia, la respuesta más fiable de las tres.



Qué modelo dejar instalado
El Qwen3-4B Q4_K_M es la recomendación para sustituir el modelo por defecto. Pesa 2,5 GB, carga bien dentro del límite de la Pi 5 de 8 GB y ofrece un razonamiento claramente superior al Qwen3.5-2B que viene preinstalado. La diferencia de velocidad, de 7 tok/seg a poco más de 4, es el precio por esa mejora de calidad. Para uso como asistente de código o consultas técnicas, ese ritmo es suficiente.
La URL de descarga, una vez creada la cuenta en Hugging Face, es:
wget --header="Authorization: Bearer hf_XXXXXXXXXX" \
"https://huggingface.co/bartowski/Qwen_Qwen3-4B-GGUF/resolve/main/Qwen_Qwen3-4B-Q4_K_M.gguf"Después de la descarga, hay que copiarlo a la Pi con scp, seleccionarlo en Settings del portal y guardar la configuración.
Las variantes Q6_K y Q8_0 del mismo modelo ofrecen mayor precisión pero caen por debajo de 3,5 tok/seg. Para sesiones de trabajo con un agente de código, ese ritmo hace la experiencia poco práctica. La cuantización Q4_K_M es el punto de equilibrio real entre calidad y velocidad en este hardware.


El modelo por defecto de Potato OS no es malo, pero tampoco es el mejor que puede correr esta placa. El Qwen3-4B Q4_K_M da un razonamiento claramente más sólido a una velocidad todavía práctica. Esa es la combinación que merece quedarse instalada.

")

