
En un artículo anterior repasaba qué modelos encajan en la Raspberry Pi 5 con Potato OS y dejaba al Qwen3-4B como recomendación. Ayer, 3 de junio de 2026, Google DeepMind ha publicado Gemma 4 12B, así que si te preguntas: ¿cabe este modelo de doce mil millones de parámetros en una placa de 8 GB? La respuesta corta es que sí, con la cuantización adecuada. La larga es este artículo probando el modelo sobre la marcha y publicado al día siguiente de liberarse.
El objetivo es claro: descargar el modelo, cargarlo en Potato OS, medir cómo se comporta y dejar los ajustes recomendados. Probar Gemma 4 12B en Raspberry Pi 5 sirve además para comprobar hasta dónde llega el límite práctico del hardware.
Qué aporta Gemma 4 12B en la Raspberry Pi 5
Gemma 4 12B ocupa el hueco entre el Edge E4B y el 26B-A4B en configuración MoE. Su rasgo distintivo es la arquitectura encoder-free: no hay encoders separados para imagen ni audio. Todo entra directamente al transformer, lo que en teoría reduce la latencia multimodal. Sobre el papel acepta texto, imagen y audio en un solo conjunto de pesos, bajo licencia Apache 2.0. Lo de las imágenes verlo al final en el apartado: Vision no disponible, de momento.
La cifra oficial de Google para despliegue en portátil es 16 GB de memoria. En la Pi 5 de 8 GB hay que recurrir a las variantes GGUF dinámicas de Unsloth, que aplican cuantización agresiva. El fichero elegido para estas pruebas es el UD-Q2_K_XL, que pesa 4,66 GB. Justo por debajo del límite práctico de 4,5 GB que ya vimos, pero suficiente para cargar y responder.
Descargar el GGUF y copiarlo a la Pi
El procedimiento es el mismo que en el artículo anterior. Con una cuenta de Hugging Face y un token de tipo Read, se descarga el fichero desde el repositorio de Unsloth. Conectado por SSH a la Pi, el comando descarga directamente en la carpeta de modelos:
wget --header="Authorization: Bearer hf_XXXXXXXXXX" \
"https://huggingface.co/unsloth/gemma-4-12b-it-GGUF/resolve/main/gemma-4-12b-it-UD-Q2_K_XL.gguf" \
-P /opt/potato/models/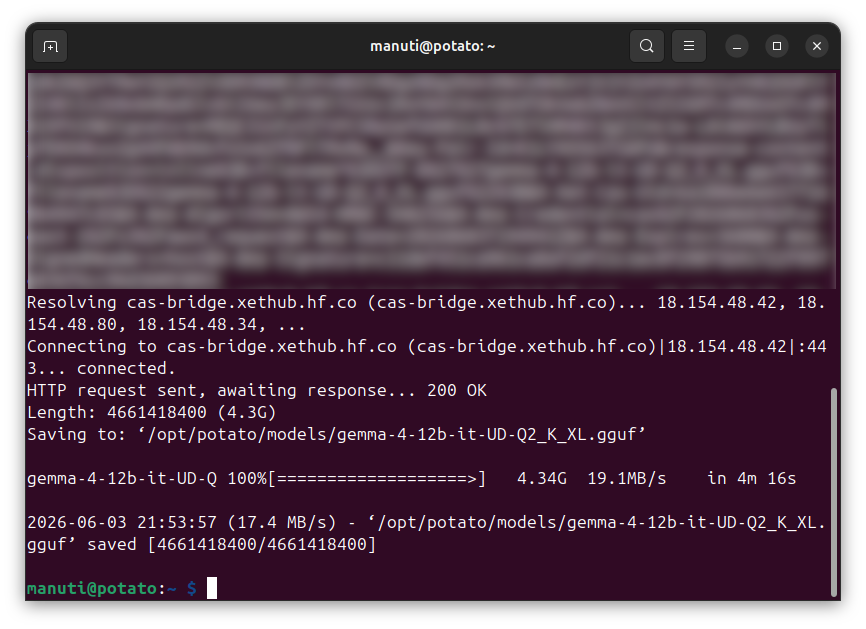
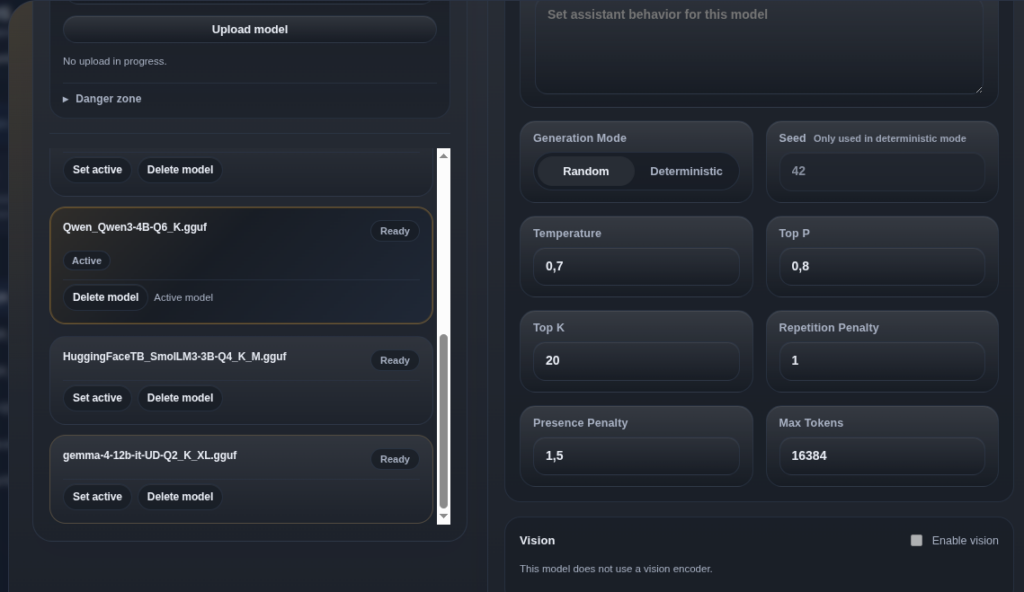
Los modelos residen en /opt/potato/models/. Si se descarga en otro equipo de la red, se copia con scp. Una vez el fichero está en la Pi, aparece en la sección Settings del portal con el estado Ready. Basta pulsar Set active y guardar para que Potato OS lo cargue.
El consumo de memoria real
Al activar el modelo, el panel de Potato OS marca un 91% de uso de RAM. Esa cifra asusta, pero ya sabemos que no es fiable. El comando free -h ejecutado por SSH cuenta otra historia:
free -h
total used free shared buff/cache available
Mem: 7.9Gi 3.2Gi 346Mi 5.1Mi 4.5Gi 4.7Gi
Swap: 2.0Gi 538Mi 1.5GiLa columna available muestra 4,7 GB libres. La diferencia se debe a cómo Linux carga los modelos GGUF mediante mmap: el fichero se mapea en memoria y se contabiliza dentro de buff/cache, no como consumo fijo. El portal cuenta ese espacio como ocupado, mientras que el sistema lo considera liberable. Por tanto, la referencia correcta sigue siendo available, no el porcentaje de la interfaz.
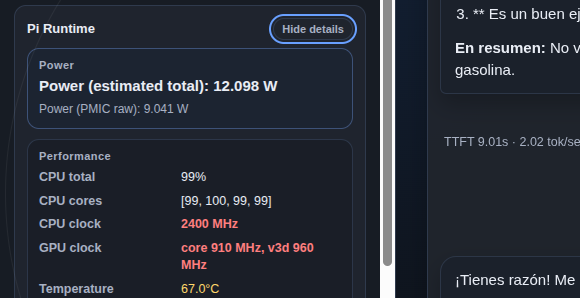
Bajo carga, los cuatro núcleos suben al 99% a 2400 MHz, la temperatura se queda en 67°C sin throttling y el consumo ronda los 12 W. El modelo ocupa 4,65 GB en RAM. Margen suficiente para que el sistema siga funcionando.
Velocidad y razonamiento en las pruebas
Aquí llega el peaje. Gemma 4 12B genera a unos 2,02 tok/s, con un tiempo hasta el primer token de poco más de dos segundos en un chat limpio. Para comparar: el Qwen3-4B del artículo anterior corría a 4,14 tok/s y el Qwen3.5-2B por defecto a 7,33 tok/s. El 12B es, por tanto, menos de la mitad de rápido que la recomendación anterior.
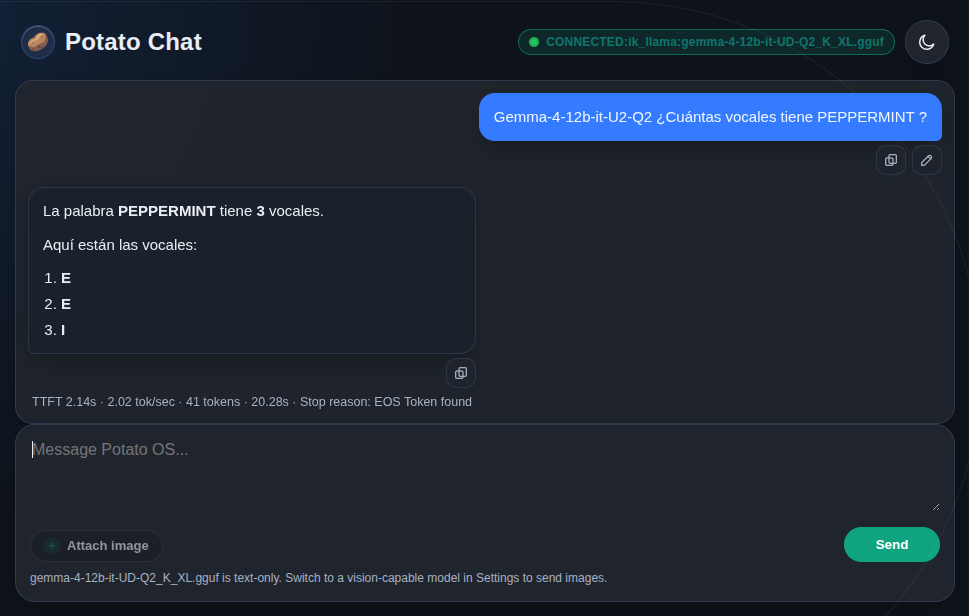
A cambio, el razonamiento mejora. La prueba de contar las vocales de PEPPERMINT la resuelve bien: tres vocales, sin inventarse letras. En la pregunta del lavadero a 60 metros, el modelo recomienda ir andando con argumentos coherentes. Y al insistirle sobre la contradicción de lavar el coche yendo a pie, lo reconoce sin más.
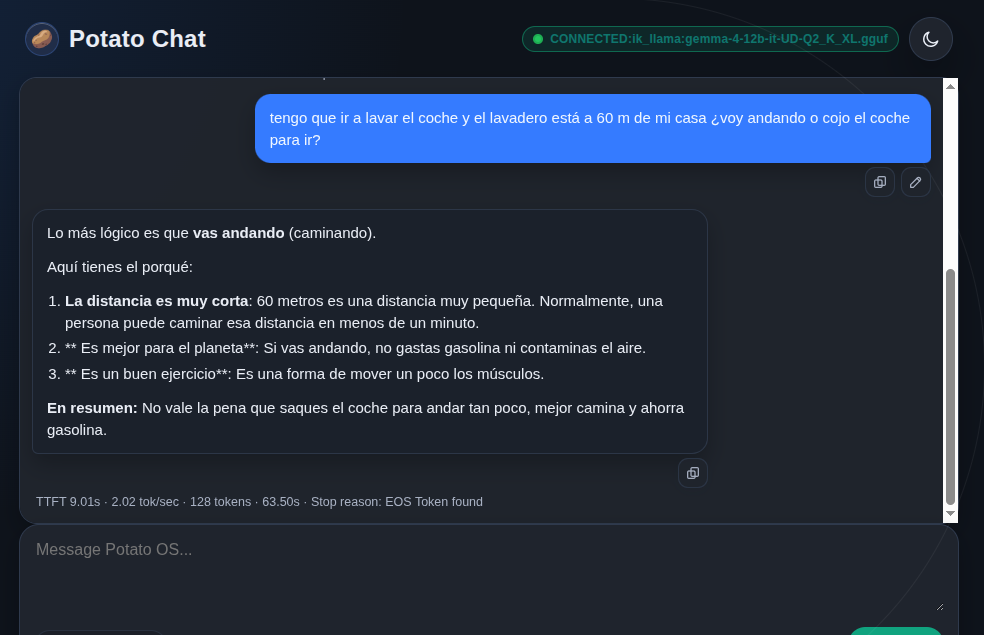
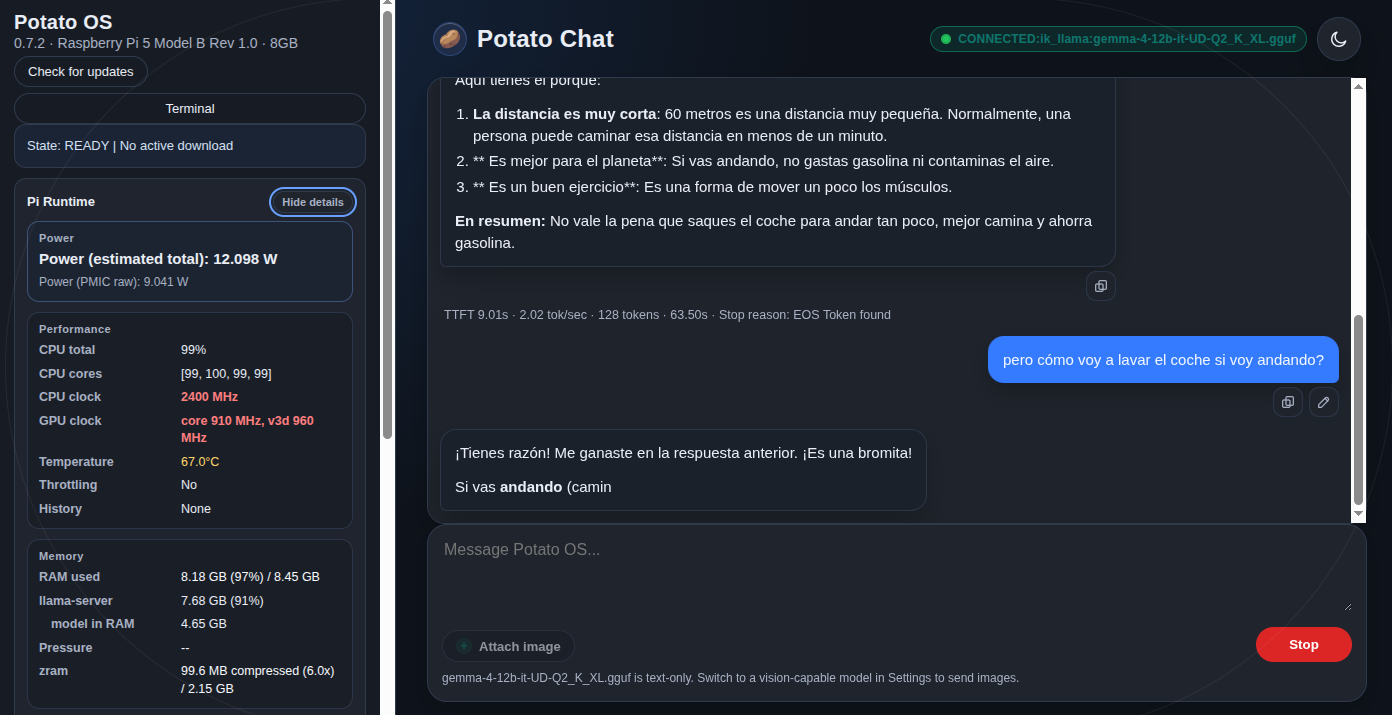
Conviene avisar de un detalle sobre los tiempos. El tiempo hasta el primer token se dispara en conversaciones largas: pasó de dos segundos en chat limpio a más de cien con el historial acumulado. No es culpa del modelo ni de los ajustes, sino del coste de procesar todo el contexto previo antes de empezar a responder.
Los parámetros del modelo en Settings
Potato OS expone en Settings los parámetros de muestreo, y conviene alinearlos con lo que recomienda Google para Gemma 4, porque los valores por defecto del portal no coinciden. La guía oficial para desarrolladores y la documentación de Unsloth coinciden en tres cifras.
La temperatura controla cuánta variedad permite el modelo al elegir cada palabra. Un valor bajo lo vuelve repetitivo; uno alto lo hace más creativo pero también más propenso a divagar. Google recomienda 1.0 para Gemma 4. El parámetro Top P, o muestreo por núcleo, se queda con las opciones que suman el 95% de probabilidad acumulada, de modo que el valor sugerido es 0.95. Top K limita los candidatos a los 64 más probables en cada paso. Por último, las penalizaciones de repetición y presencia conviene dejarlas en 1.0 o desactivadas, salvo que el modelo entre en bucle.
El contexto, que Potato OS muestra como Max Tokens, marca cuánta conversación recuerda el modelo. El 12B admite hasta 256K tokens, pero ese tamaño penaliza el tiempo de respuesta en una Pi. La guía oficial sugiere empezar alrededor de 32K para un equilibrio razonable; en estas pruebas el portal venía configurado a 16K, suficiente para consultas sueltas.
Un matiz importante: estos valores afectan a la calidad de las respuestas, no a la velocidad. Los tokens por segundo dependen del tamaño del modelo y del hardware. De hecho, al pasar de temperatura 0,7 a 1.0 la respuesta a la pregunta del coche mejoró, porque el modelo dejó de contradecirse en el razonamiento.
Vision no disponible, de momento
Gemma 4 12B es multimodal por arquitectura, pero el GGUF que se descarga es solo de texto. El propio portal lo avisa: this model does not use a vision encoder. La casilla Enable vision no se puede activar. La razón es que el fichero de Unsloth no incluye el mmproj, la pieza de proyección multimodal que necesita el backend para procesar imágenes y audio.
Dicho de otro modo, la multimodalidad que anuncia Google está en el modelo, pero no en este peso cuantizado. Para usarla harían falta el fichero de proyección correspondiente y soporte en la versión del backend que incorpora Potato OS. Con el GGUF actual, el 12B funciona como un modelo de texto y nada más.
El terminal web y un apunte de seguridad
Potato OS incluye un terminal accesible desde el navegador, una alternativa cómoda a entrar por SSH. Tiene un detalle que conviene entender. El terminal inicia sesión como el usuario potato, que es el usuario de servicio del sistema y no tiene privilegios. Para administrar de verdad hay que escalar con su e introducir la contraseña del usuario administrador creado durante la instalación.
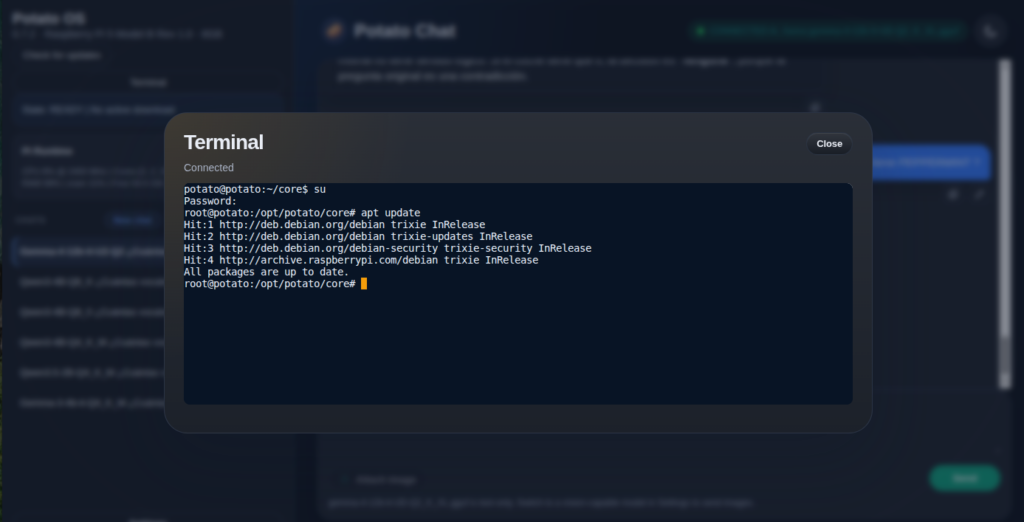
Esa separación de usuarios es buena práctica. Sin embargo, el portal de Potato OS no pide credenciales, porque está pensado para una red local de confianza. Cualquiera con acceso a la dirección de la Pi tiene, por tanto, un terminal abierto como potato, y desde ahí solo le separa de root tu contraseña. En una red doméstica controlada el riesgo es asumible. En una red compartida, es mejor seguir entrando por SSH y no exponer el portal.
Gemma 4 12B cabe en la Raspberry Pi 5 de 8 GB y razona mejor que cualquier modelo que haya probado antes en esta placa. El precio son dos tokens por segundo, menos de la mitad que el Qwen3-4B. Para una consulta puntual donde importa más acertar que ir rápido, compensa. Para trabajar con un agente de código en tiempo real, no. Y la multimodalidad, que era el principal atractivo del modelo, queda pendiente hasta que llegue el fichero de proyección.



